Error Handling
Implementation
In this module, you’ll setup AWS Lambda to process data and handle errors when processing data from the
wildrydes created earlier. There are couple of approaches for error handling.
Resources
1. Error Handling with Retry Settings
AWS Lambda can reprocess batches of messages from Kinesis Data Streams when an error occurs in one of the items in the batch. You can configure the number of retries by configuring Retry attempts and/or Maximum age of record. The batch will be retried until the number of retry attempts or until the expiration of the batch. You can also configure On-failure destination which will be used by Lambda to send metadata of your failed invocation. You can send this metadata of the failed invocation to either an Amazon SQS queue or an Amazon SNS topic. Typically there are two kinds of errors in the data stream. One category belongs to transient errors which are temporary in nature and are successfully processed with retry logic. Second category belongs to Poison Pill (either data quality / data that generates an exception in Lambda code) which are permanent in nature. In this case Lambda retries for the configured retry attempts and then discards the records to the On-failure destination.
In order to simulate poison pill message, We will introduce an error data in streaming data and throw an error when it is found in the message. In real world, this may be a validation or a call to another service which expects certain information in the record. This is the code change that will be introduced in the Lambda function
if (item.InputData.toLowerCase().includes(errorString)) {
console.log("Error record is = ", item);
throw new Error("kaboom");
}
✅ Step-by-step Instructions
-
Go to the AWS Management Console, choose Services then select Lambda under Compute. Alternatively, you can use the search bar and type Lambda in the search dialog box.
-
Click the
WildRydesStreamProcessorfunction -
Scroll down to the Function Code section.
-
Double click the index.js file to open it in the editor
-
Copy and paste the JavaScript code below into the code editor, replacing all of the existing code.
"use strict"; const AWS = require("aws-sdk"); const dynamoDB = new AWS.DynamoDB.DocumentClient(); const tableName = process.env.TABLE_NAME; // This is used to mimic poison pill messages const errorString = "error"; // Entrypoint for Lambda Function exports.handler = function (event, context, callback) { console.log( "Number of Records sent for each invocation of Lambda function = ", event.Records.length ); const requestItems = buildRequestItems(event.Records); const requests = buildRequests(requestItems); Promise.all(requests) .then(() => callback(null, `Delivered ${event.Records.length} records`) ) .catch(callback); }; // Build DynamoDB request payload function buildRequestItems(records) { return records.map((record) => { const json = Buffer.from(record.kinesis.data, "base64").toString( "ascii" ); const item = JSON.parse(json); //Check for error and throw the error. This is more like a validation in your usecase if (item.InputData.toLowerCase().includes(errorString)) { console.log("Error record is = ", item); throw new Error("kaboom"); } return { PutRequest: { Item: item, }, }; }); } function buildRequests(requestItems) { const requests = []; // Batch Write 25 request items from the beginning of the list at a time while (requestItems.length > 0) { const request = batchWrite(requestItems.splice(0, 25)); requests.push(request); } return requests; } // Batch write items into DynamoDB table using DynamoDB API function batchWrite(requestItems, attempt = 0) { const params = { RequestItems: { [tableName]: requestItems, }, }; let delay = 0; if (attempt > 0) { delay = 50 * Math.pow(2, attempt); } return new Promise(function (resolve, reject) { setTimeout(function () { dynamoDB .batchWrite(params) .promise() .then(function (data) { if (data.UnprocessedItems.hasOwnProperty(tableName)) { return batchWrite( data.UnprocessedItems[tableName], attempt + 1 ); } }) .then(resolve) .catch(reject); }, delay); }); } -
Click Deploy to deploy the changes to the
WildRydesStreamProcessorLambda function. -
Remove the existing Kinesis Data Stream mapping by clicking the Configuration Tab above the code editor. (This step is needed only if there is an existing Kinesis Data Stream mapping or any other Event Source Mapping present for the Lambda function). In the Configuration Tab, Select the
Kinesis:wildrydes (Enabled). If the trigger is not enabled, press refresh. Delete the trigger.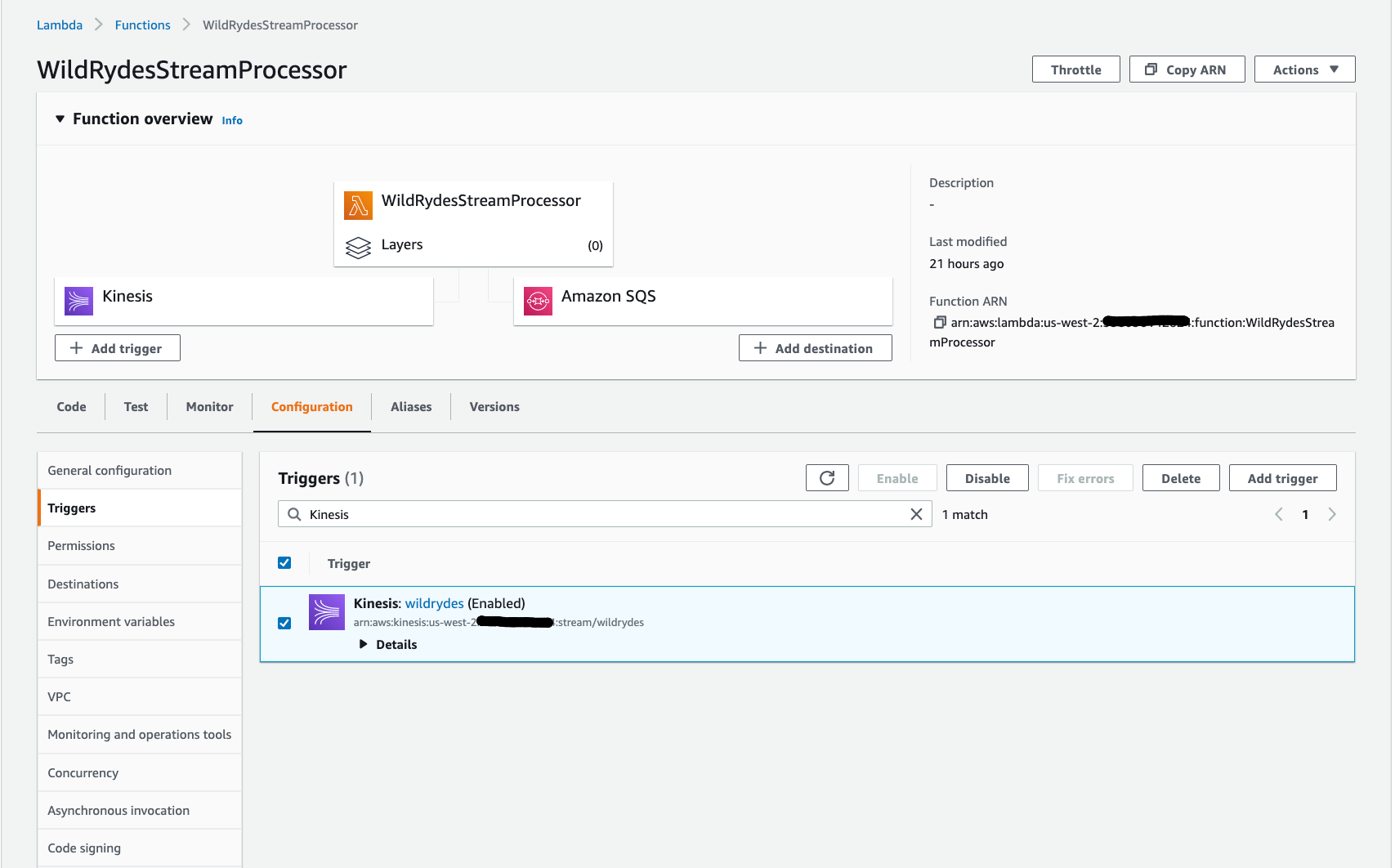
-
Add a new Kinesis Data Stream mapping by clicking the Configuration Tab.
-
Select the Triggers section and Add trigger button.
-
Select Kinesis for the service and
wildrydesfrom Kinesis Stream. -
Set the Batch size set to 10 and Starting position set to Latest. This small batch size will help us monitor the AWS Lambda error handling clearly from Cloudwatch logs
-
Set the Batch window to 15. This window will help you batch the incoming messages by waiting for 15 seconds. By default, AWS Lambda will poll messages from Amazon Kinesis Data Stream every 1 sec.
-
Open the Additional settings section.
-
Under On-failure destination add the ARN of the
wildrydes-queueSQS queue. -
Change Retry attempts to 2 and Maximum age of record to 60.
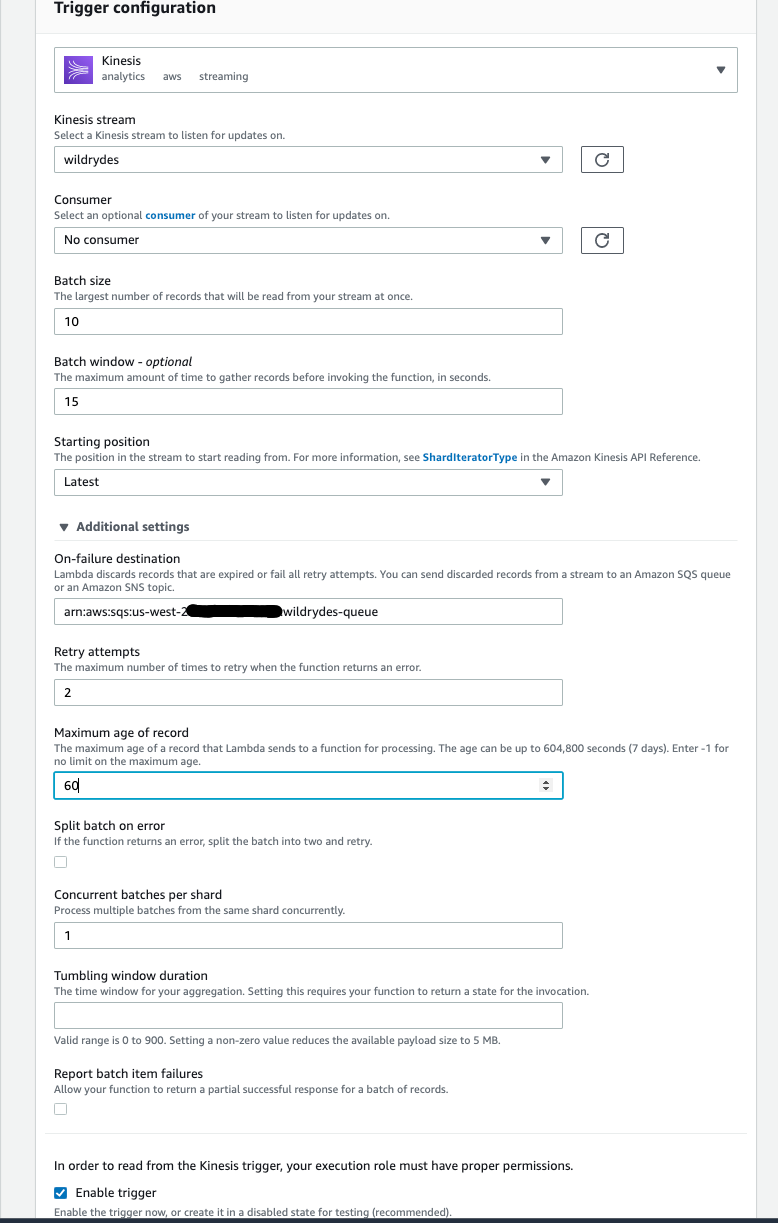
-
Leave the rest of the fields to default values.
-
Click Add to create the trigger.
-
Click the refresh button until creation is complete and the function shows as Enabled. (You may need to hit the refresh button to refresh the status)
-
Return to AWS Cloud9 environment and Insert data into Kinesis Data Stream by running producer binary.
./producer -stream wildrydes -error yes -msgs 9 -
Return to the AWS Lambda function console. Click on the Monitor tab and explore the metrics available to monitor the function.
-
Click on View logs in CloudWatch to explore the logs in CloudWatch for the log group /aws/lambda/WildRydesStreamProcessor
-
In the logs you can observe that, there will be error and the same batch will be retried twice ( as we configured
retry-attemptsto 2)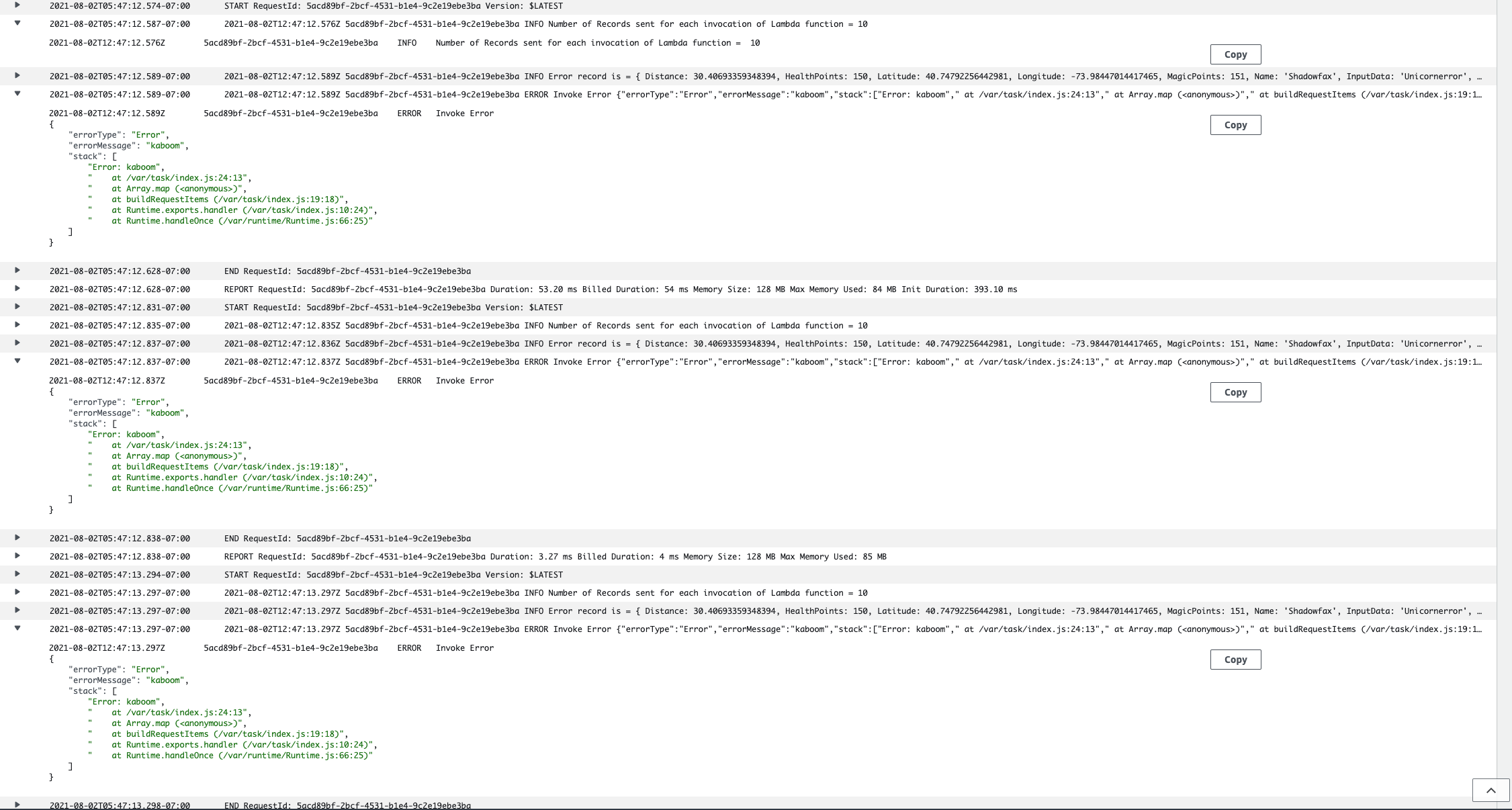
-
Since the entire batch failed, you should not notice any new records in the DynamoDB table
UnicornSensorData. You will see only the 20 records that are inserted from the previous section. -
Optionally you can Monitor SQS Queue by following the following steps.
-
Go to the AWS Management Console, choose Services then search for Simple Queue Service and select the Simple Queue Service.
-
There will be a message in the
wildrydes-queue. This is the discarded batch that had one permanent error in the batch. -
Click
wildrydes-queue. -
Click Send and recieve messages on the top right corner
-
Click Poll for messages on the bottom right corner
-
You’ll observe one message. Click the message ID and choose the Body tab. You can see all the details of the discarded batch. Notice that entire batch of messages(Size:9) is discarded even through there was only one error message.
-
Check the checkbox beside the message ID
-
Click Delete button. This will delete the message from the SQS queue. This step is optional and is needed only to keep the SQS queue empty.
2. Error Handling with Bisect On Batch settings
The retry setting we had before discards entire batch of records even if there is one bad record in the batch. Bisect On Batch error handling feature of AWS Lambda splits the batch into two and retries the half-batches separately. The process continues recursively until there is a single item in a batch or messages are processed successfully.
-
There are no code changes to the
WildRydesStreamProcessorLambda function. The only change is around setting Kinesis Data Stream configuration. Follow the below steps to remove and add a new Kinesis Data Stream mapping. -
Remove the existing Kinesis Data Stream mapping by clicking the Configuration Tab above the code editor. (This step is needed only if there is an existing Kinesis Data Stream mapping or any other Event Source Mapping present for the Lambda function). In the Configuration Tab select the
Kinesis:wildrydes (Enabled)and Delete the trigger. -
Add a new Kinesis Data Stream mapping by clicking the Configuration Tab.
-
Select the Triggers section and Add trigger button.
-
Select Kinesis for the service and
wildrydesfrom Kinesis Stream. -
Set the Batch size set to 10 and Starting position set to Latest. This small batch size will help us monitor the AWS Lambda error handling clearly from Cloudwatch logs
-
Set the Batch window to 15. Again, this window will help you batch the incoming messages by waiting for 15 seconds.
-
Open the Additional settings section.
-
Under On-failure destination add the ARN of the
wildrydes-queueSQS queue. -
Change Retry attempts to 2 and Maximum age of record to 60.
-
Check the box Split batch on error.
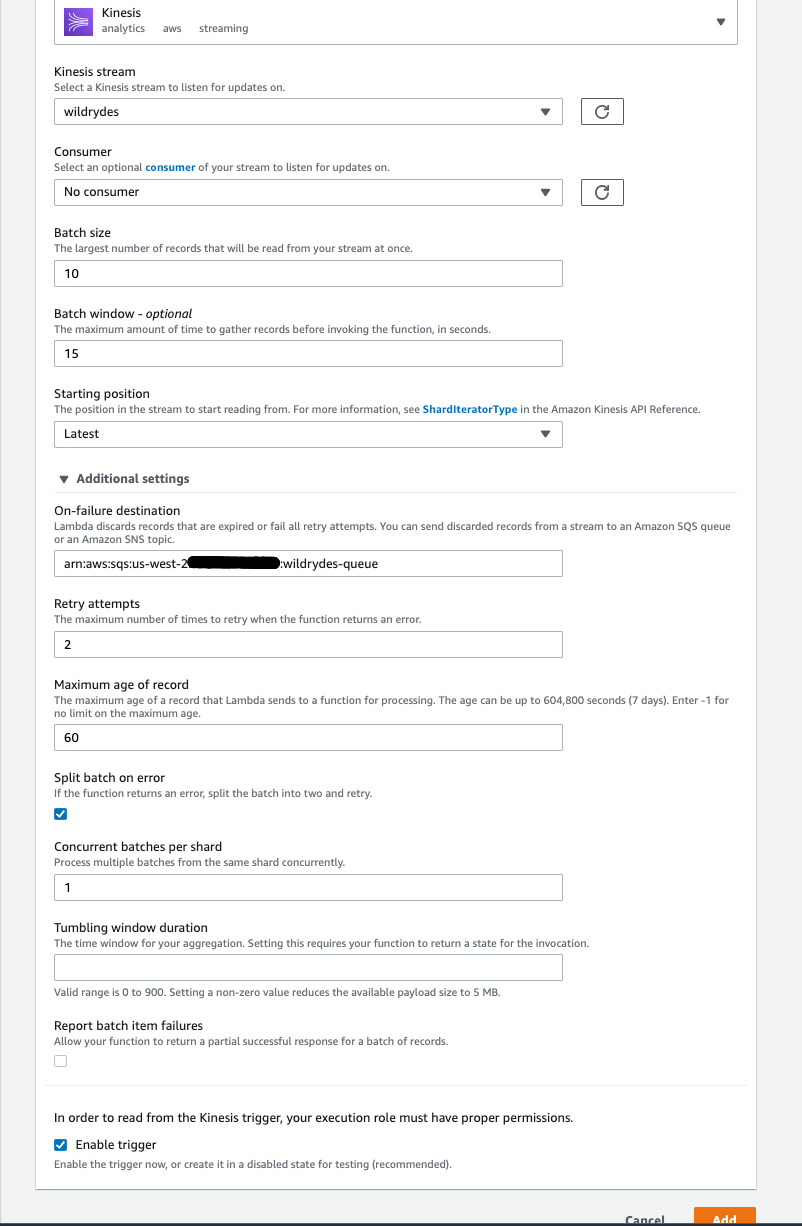
-
Leave the rest of the fields to default values.
-
Click Add to create the trigger.
-
Click the refresh button until creation is complete and the function shows as Enabled. (You may need to hit the refresh button to refresh the status)
-
Return to AWS Cloud9 environment and Insert data into Kinesis Data Stream by running producer binary.
./producer -stream wildrydes -error yes -msgs 9
-
Return to the AWS Lambda function console. Click on the Monitor tab and explore the metrics available to monitor the function.
-
Click on View logs in CloudWatch to explore the logs in CloudWatch for the log group /aws/lambda/WildRydesStreamProcessor
-
In the logs you can observe that, there will be error and the same batch will be split into two halves and processed. This splitting continues recursively until there is a single item or messages are processed successfully.
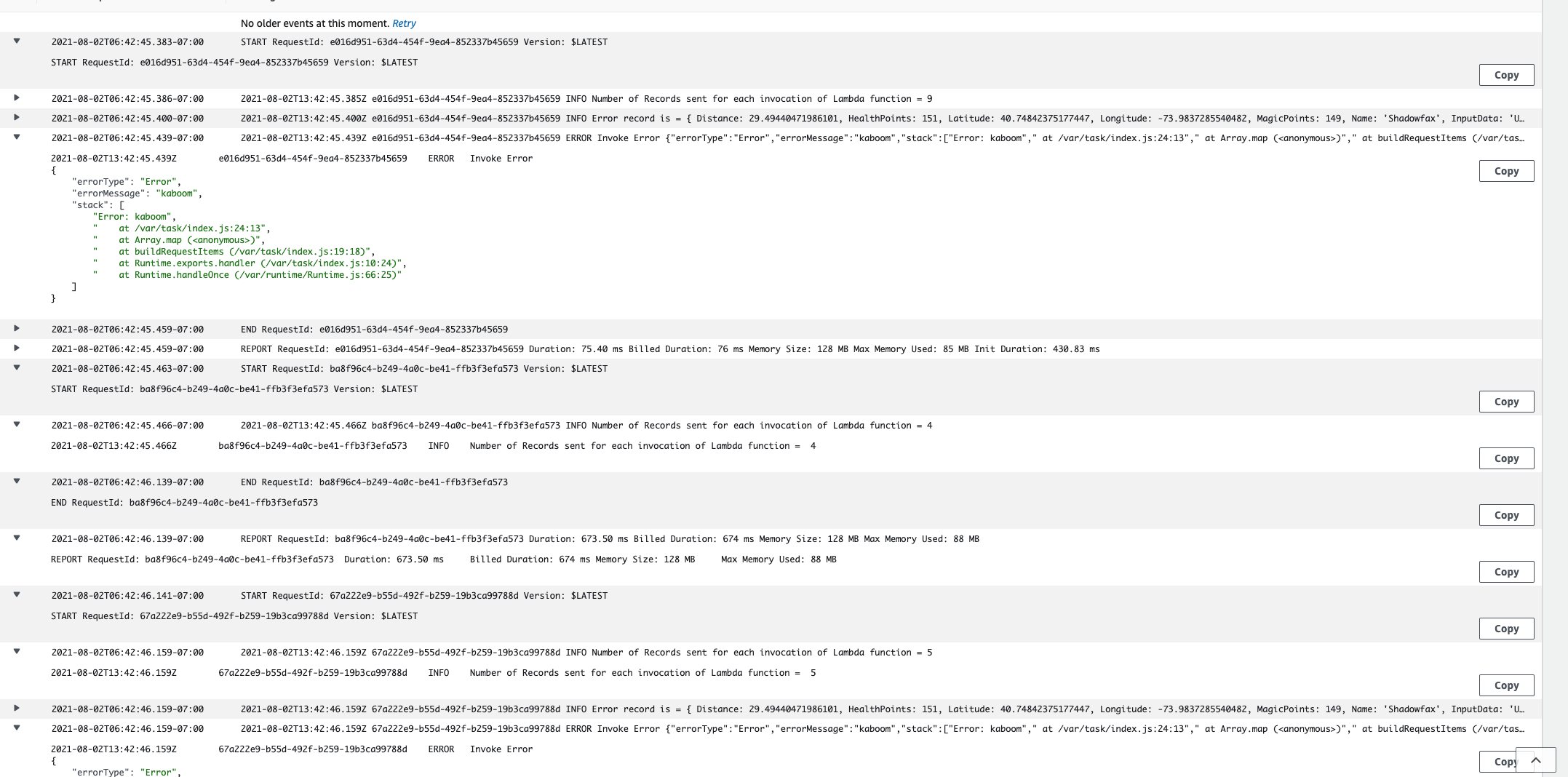
-
Since Bisect-On-Batch splits the batch and processes records,you should notice new records in the DynamoDB table
UnicornSensorData. There should be a total of 28 items inUnicornSensorData( 1 record is an error record ). -
Optionally you can Monitor SQS Queue by following the below steps.
-
Go to the AWS Management Console, choose Services then search for Simple Queue Service and select the Simple Queue Service.
-
There will be a message in the
wildrydes-queue. This is the discarded batch that had one permanent error in the batch. -
Click
wildrydes-queue. -
Click Send and recieve messages on the top right corner
-
Click Poll for messages on the bottom right corner
-
You’ll observe one message. Click the message ID and choose the Body tab. You can see all the details of the discarded batch. Notice that this time only one message is discarded.
-
Check the checkbox beside the message ID
-
Click Delete button. This will delete the message from the SQS queue. This step is optional and is needed only to keep the SQS queue empty.
-
Next
✅ Proceed to the next module, Tumbling Window, wherein you’ll explore the tumbling window feature of AWS Lambda to aggregate sensor data.