Setup
Implementation
In this module, you’ll setup all of the resources needed to support processing
records from the Kinesis Data Stream wildrydes
including a Dynamo DB table, a Lambda function, an IAM role, a Kinesis Data
Stream, and a SQS queue.
Resources
- Create a Dynamo DB Table
- Create an SQS On-Error Destination Queue
- Create an IAM Role
- Create a Lambda Function
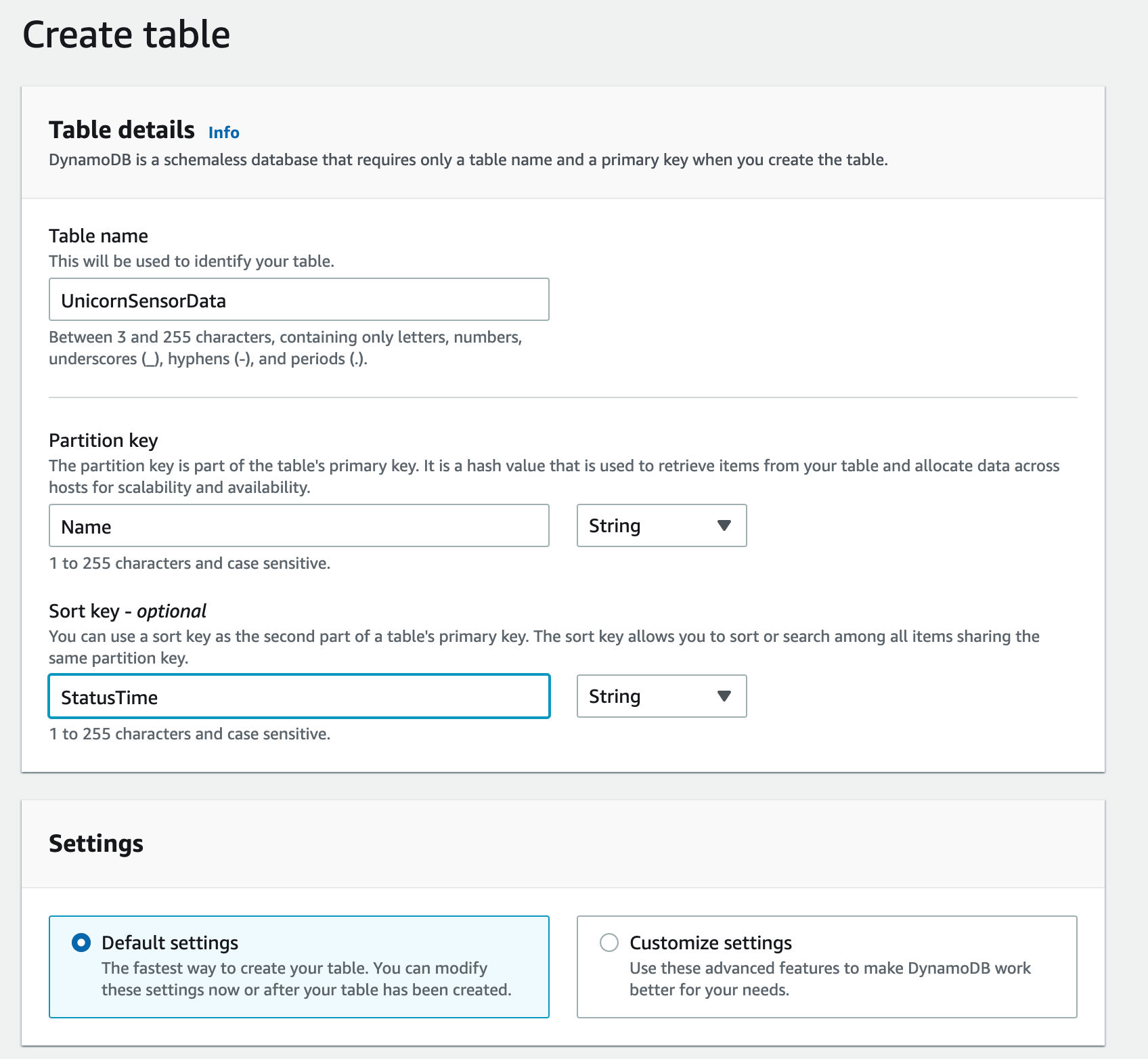
1. Create an Amazon DynamoDB table
Use the Amazon DynamoDB console to create a new DynamoDB table. This table is used to store the unicorn data from the AWS Lambda function. We will call your table
UnicornSensorData and give it a Partition key called Name of type
String and a Sort key called StatusTime of type String. Use the
defaults for all other settings.
After you’ve created the table, note the Amazon Resource Name (ARN) for use in the next section.
✅ Step-by-step Instructions
-
Go to the AWS Management Console, choose Services then select DynamoDB under Database. Alternatively, you can use the search bar and type DynamoDB in the search dialog box.
-
Click Create table.
-
Enter
UnicornSensorDatafor the Table name. -
Enter
Namefor the Partition key and select String for the key type. -
Enter
StatusTimefor the Sort key and select String for the key type. -
Leave the Use default settings box checked and choose Create.
-
Once the table is created, Click on the hyperlink on the table name. This will take you to the new screen. Under General information, You will see Amazon Resource Name (ARN). Copy and save the Amazon Resource Name (ARN) in the scratchpad. You will use this when creating IAM role.
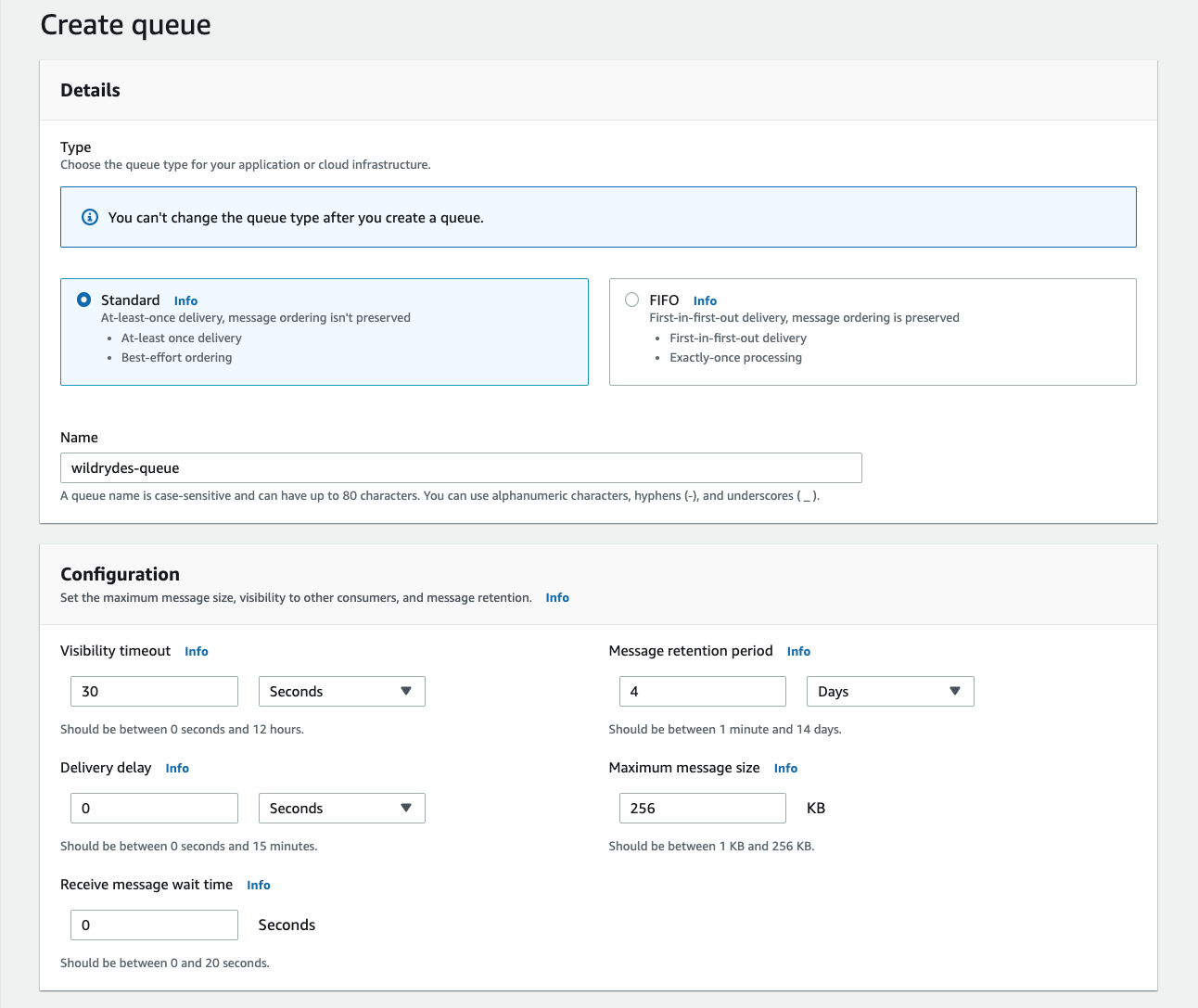
2. Create an SQS On-Error Destination Queue
Use the Amazon SQS console to create a new queue nammed wildrydes-queue. Your Lambda function will send messages to this queue when the processing is failed based on the retry settings.
After you’ve created the queue, note the Amazon Resource Name (ARN) for use in later sections.
✅ Step-by-step Instructions
-
Go to the AWS Management Console, choose Services then select Simple Queue Service under Application Integration. Alternatively, you can use the search bar and type Simple Queue Service in the search dialog box.
-
Click the orange Create queue button
-
For the Name field enter
wildrydes-queue -
Leave the rest of the options as the defaults and click “Create queue”
-
Copy and save the ARN of the SQS queue in the scratchpad as you will need it for Lambda configuration
3. Create an IAM role for your Lambda function
Use the IAM console to create a new role. Name it WildRydesStreamProcessorRole
and select Lambda for the role type. Create a policy that allows dynamodb:BatchWriteItem access to
the DynamoDB table created in the last section and sqs:SendMessage to send failed messages to DLQ and attach it to the new role.
Also, Attach the managed policy called
AWSLambdaKinesisExecutionRole to this role in order to grant permissions for
your function to read from Amazon Kinesis streams and to log to Amazon
CloudWatch Logs.
✅ Step-by-step Instructions
-
From the AWS Console, click on Services and then select IAM in the Security, Identity & Compliance section. Alternatively, you can use the search bar and type IAM in the search dialog box.
-
Select Policies from the left navigation and then click Create policy.
-
Using the Visual editor, we’re going to create an IAM policy to allow our Lambda function access to the DynamoDB table created in the last section. To begin, click Service, begin typing DynamoDB in Find a service, and click DynamoDB.
-
Click Action, begin typing BatchWriteItem in Filter actions, and tick the BatchWriteItem checkbox.
-
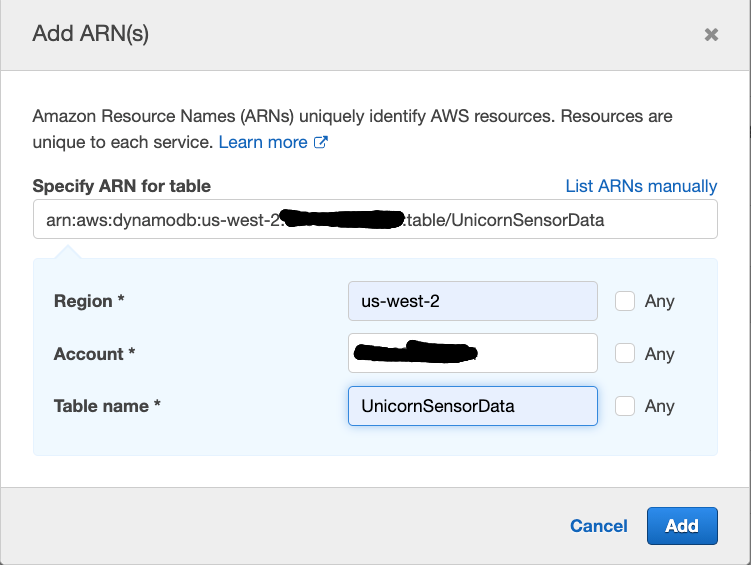
Click Resources, click Add ARN in table, Copy the ARN of the DyanamoDB table from the scratchpad and paste it in
Specify ARN for table. Alternatively, you can construct the ARN of the DynamoDB table you created in the previous section by specifying the Region, Account, and Table Name.In Region, enter the AWS Region in which you created the DynamoDB table in the previous section, e.g.:
us-east-1.In Table Name, enter
UnicornSensorData.You should see your ARN in the Specify ARN for table field and it should look similar to:
-
Click Add.
When completed, your console should look similar to this:
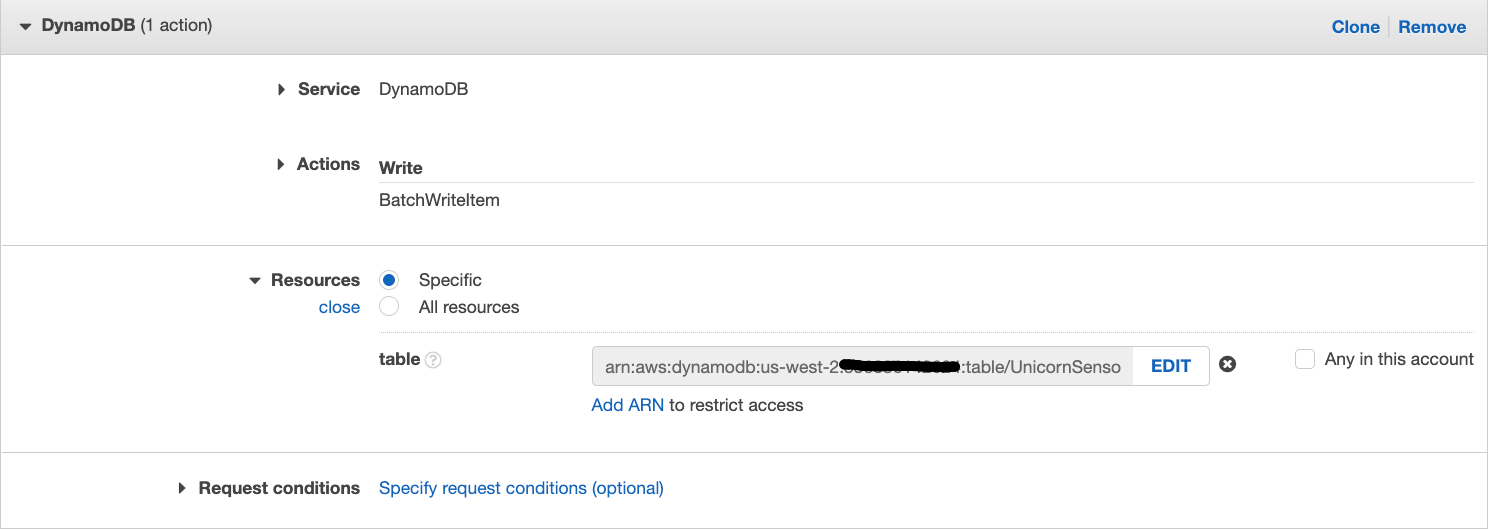
-
Next we are going to add permissions to allow the Lambda function access to the SQS On-Error Destination Queue. Click Add additional permissions click Service begin typing SQS in Find a service and click SQS.
-
Click Action begin typing SendMessage in Filter actions, and tick the SendMessage checkbox.
-
Click Resources, click Add ARN in queue. Copy the ARN of the SQS queue from the scratchpad and paste it in Specify ARN for queue. Alternatively, you can construct the ARN of the SQS queue you created in the previous section by specifying the Region, Account, and Queue Name.
In **Region**, enter the AWS Region in which you created the SQS queue in the previous section, e.g.: us-east-1. In **Queue Name**, enter `wildrydes-queue`. You should see your ARN in the **Specify ARN for queue** field and it should look similar to:  -
Click Next: Tags**.
-
Click Next: Review**.
-
Enter
WildRydesDynamoDBWritePolicyin the Name field. -
Click Create policy.
-
Select Roles from the left navigation and then click Create role.
-
Click Lambda for the role type from the AWS service section.
-
Click Next: Permissions.
-
Begin typing
AWSLambdaKinesisExecutionRolein the Filter text box and check the box next to that role. -
Begin typing
WildRydesDynamoDBWritePolicyin the Filter text box and check the box next to that policy. -
Click Next.
-
Enter
WildRydesStreamProcessorRolefor the Role name. -
Click Create role.
-
Begin typing
WildRydesStreamProcessorRolein the Search text box
-
Click on WildRydesStreamProcessorRole and it should look similar to:
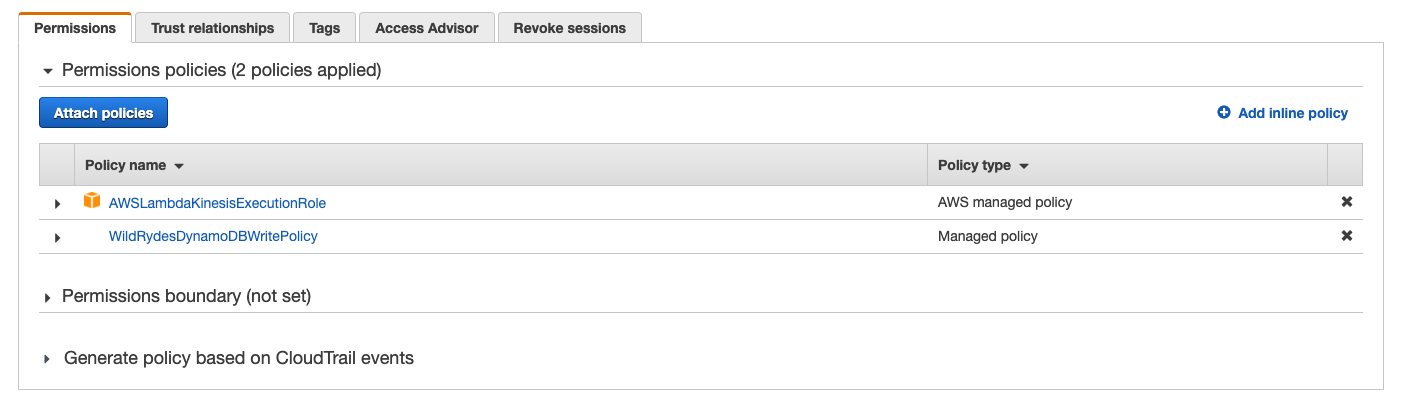
4. Create a Lambda function to process the stream
Create a Lambda function called WildRydesStreamProcessor that will be
triggered whenever a new record is avaialble in the wildrydes stream. Use
the provided index.js implementation for your function code. Create an
environment variable with the key TABLE_NAME and the value
UnicornSensorData. Configure the function to use the
WildRydesStreamProcessor role created in the previous section.
✅ Step-by-step Instructions
-
Go to the AWS Management Console, choose Services then select Lambda under Compute. Alternatively, you can use the search bar and type Lambda in the search dialog box.
-
Click Create function.
-
Enter
WildRydesStreamProcessorin the Function name field. -
Select Node.js 14.x from Runtime.
-
Select WildRydesStreamProcessorRole from the Existing role dropdown.
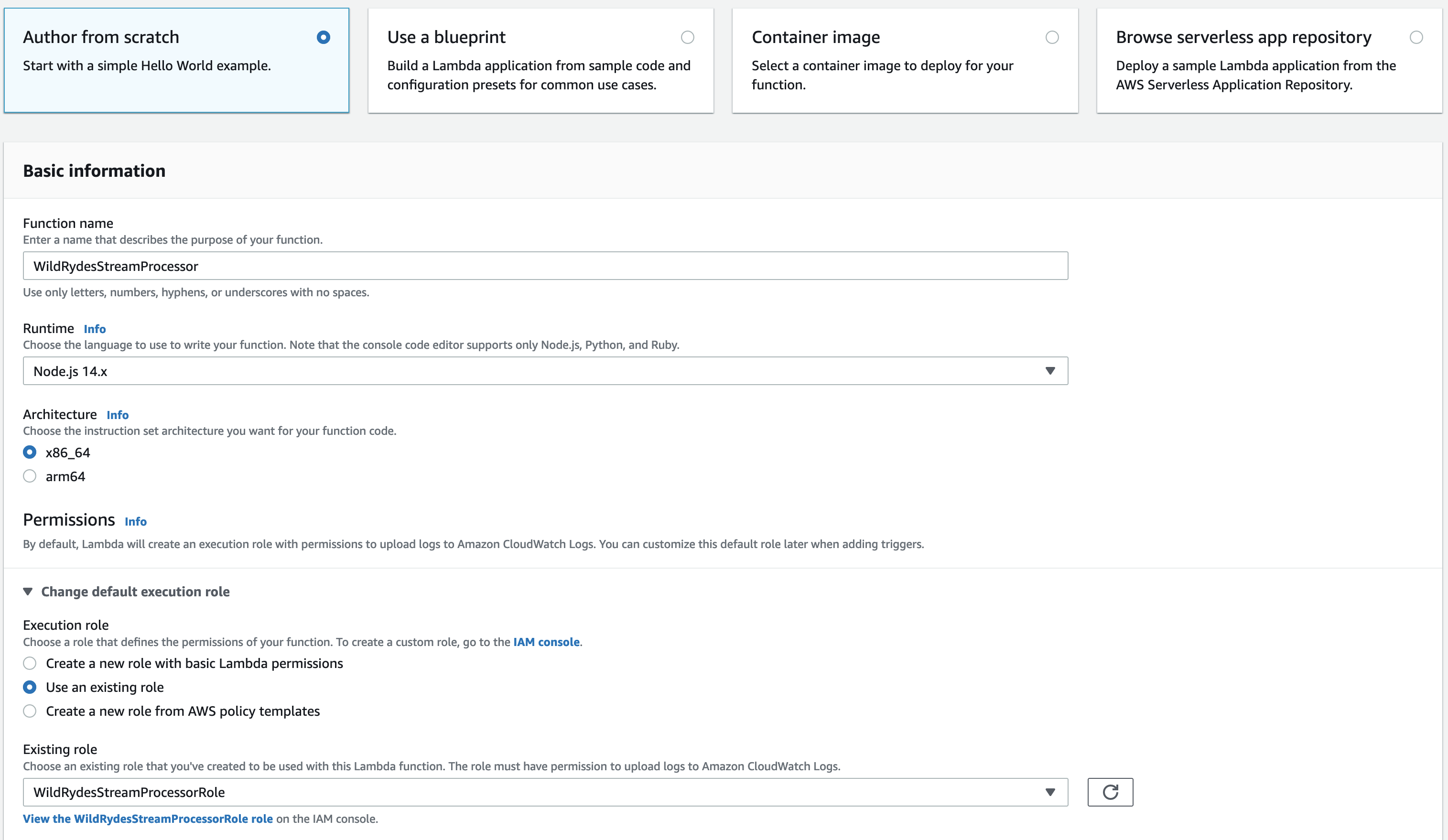
-
Click Create function.
-
Scroll down to the Code source section.
-
Copy and paste the JavaScript code below into the code editor.
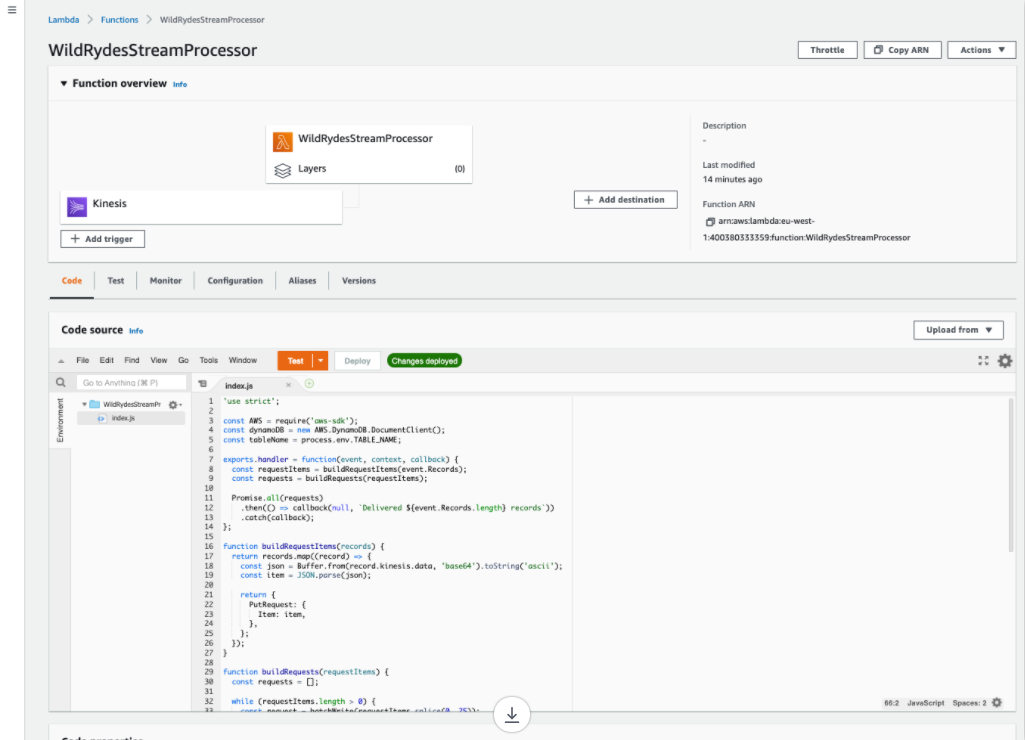
"use strict"; const AWS = require("aws-sdk"); const dynamoDB = new AWS.DynamoDB.DocumentClient(); const tableName = process.env.TABLE_NAME; // Entrypoint for Lambda Function exports.handler = function (event, context, callback) { const requestItems = buildRequestItems(event.Records); const requests = buildRequests(requestItems); Promise.all(requests) .then(() => callback(null, `Delivered ${event.Records.length} records`) ) .catch(callback); }; // Build DynamoDB request payload function buildRequestItems(records) { return records.map((record) => { const json = Buffer.from(record.kinesis.data, "base64").toString( "ascii" ); const item = JSON.parse(json); return { PutRequest: { Item: item, }, }; }); } function buildRequests(requestItems) { const requests = []; // Batch Write 25 request items from the beginning of the list at a time while (requestItems.length > 0) { const request = batchWrite(requestItems.splice(0, 25)); requests.push(request); } return requests; } // Batch write items into DynamoDB table using DynamoDB API function batchWrite(requestItems, attempt = 0) { const params = { RequestItems: { [tableName]: requestItems, }, }; let delay = 0; if (attempt > 0) { delay = 50 * Math.pow(2, attempt); } return new Promise(function (resolve, reject) { setTimeout(function () { dynamoDB .batchWrite(params) .promise() .then(function (data) { if (data.UnprocessedItems.hasOwnProperty(tableName)) { return batchWrite( data.UnprocessedItems[tableName], attempt + 1 ); } }) .then(resolve) .catch(reject); }, delay); }); }
-
Now, You will be adding the DynamoDB table name as an environment variable. In the Configuration tab, select the Environment variables section.
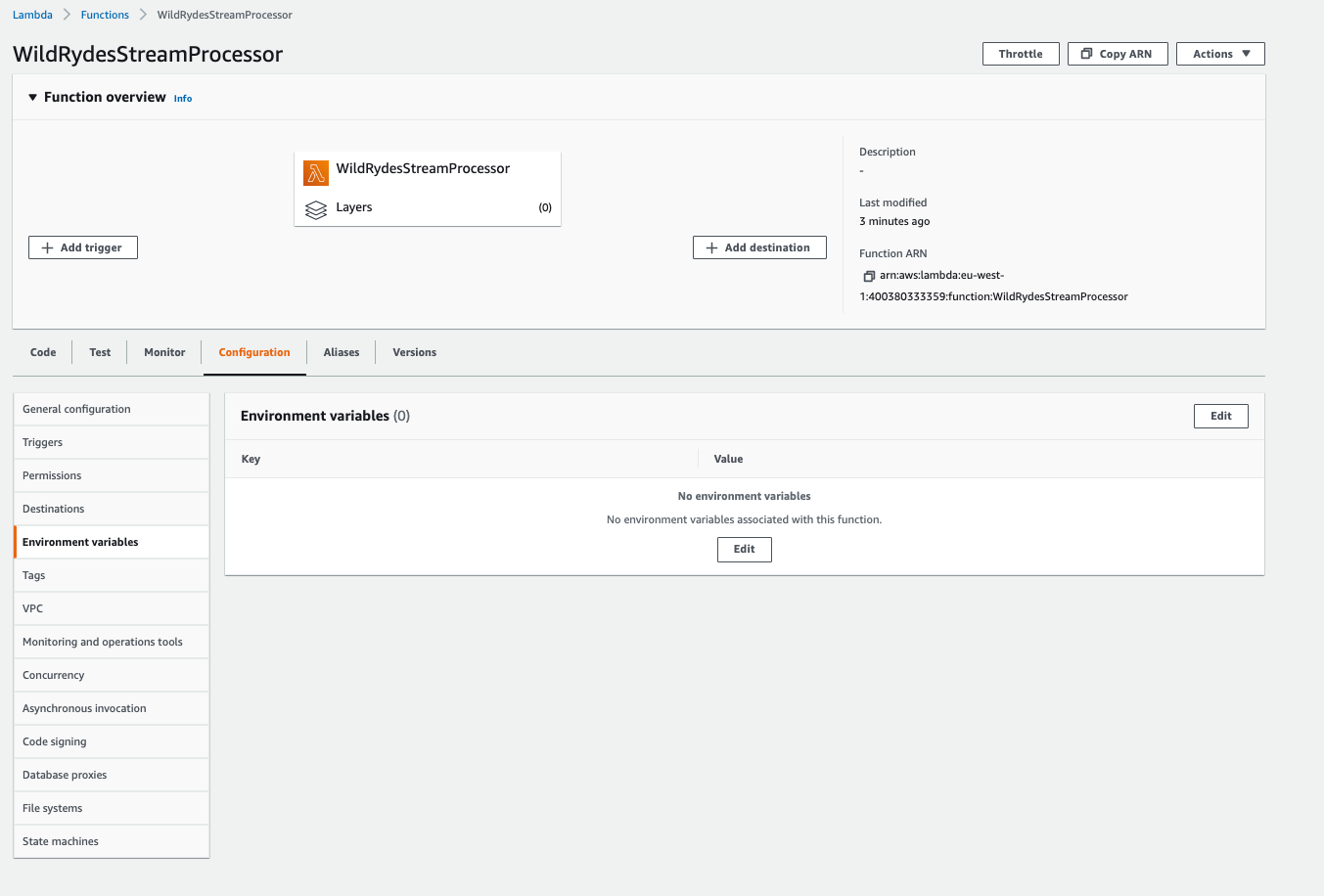
-
Click Edit and then Add environment variable
-
Enter
TABLE_NAMEin Key andUnicornSensorDatain Value. -
Add another environment variable called
AWS_NODEJS_CONNECTION_REUSE_ENABLEDin Key and1in Value. This setting helps to reuse TCP connection. You can learn more here -
click Save.
-
-
Now, You will add the event source mapping(ESM) for AWS Lambda to integrate with Kinesis. Scroll up and click on Add Trigger from the Function overview section.
-
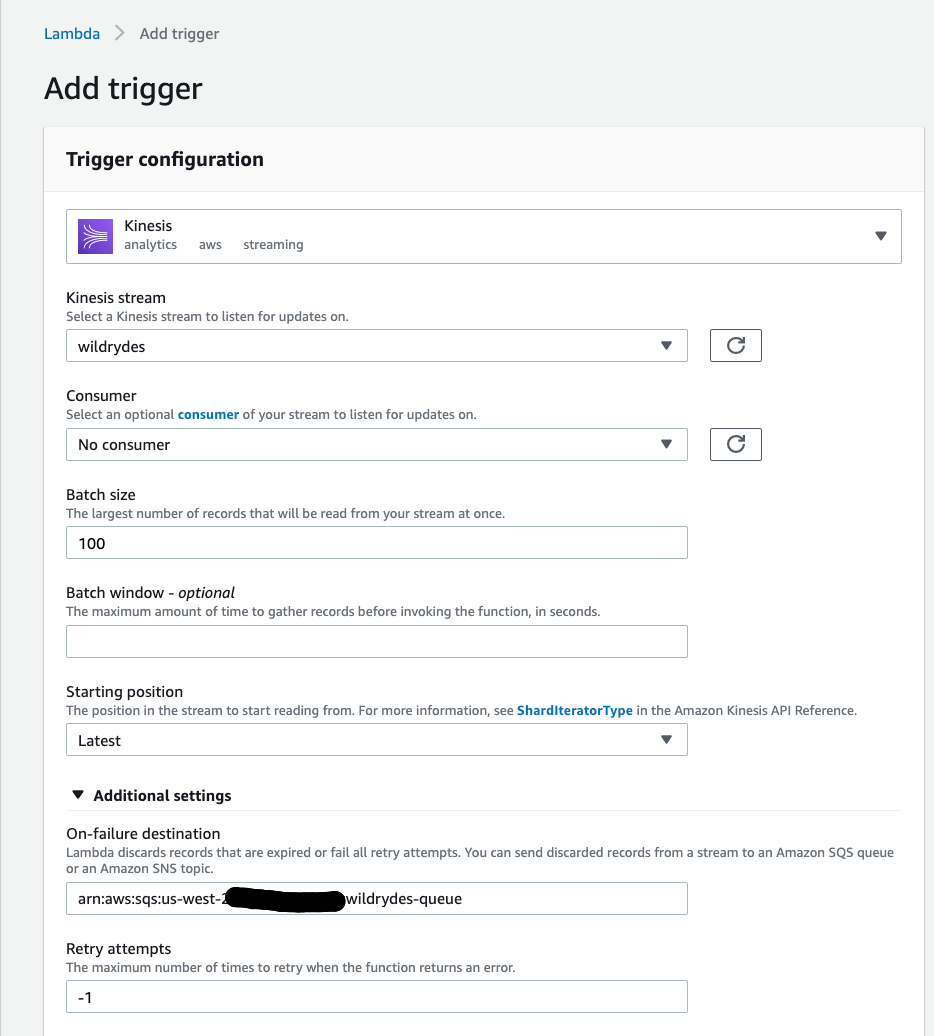
In the Trigger configuration section, select Kinesis.
-
Select
wildrydesfrom Kinesis stream. -
Leave Batch size set to 100 and Starting position set to Latest.
-
Open the Additional settings section
-
Under On-failure destination add the ARN of the wildrydes-queue SQS queue
-
Make sure Enable trigger is checked.
-
Click Add.
-
Go back to Code Tab and Deploy the Lambda function - the screen will provide a message on successful deployment.
⭐ Recap
🔑 You can subscribe Lambda functions to automatically read batches of records off your Kinesis stream and process them if records are detected on the stream.
🔧 In this module, you’ve setup a DynamoDB table for storing unicorn data, a Dead Letter Queue(DLQ) for recieving failed messages and a Lambda function to read data from Kinesis Data Stream and store in DynamoDB.
Next
✅ Proceed to the next module, Stream Processing, wherein you’ll use the Lambda funtion you created just now to process the stream and store in DynamoDB. You will also verify the process.