Serverless Data Processing on AWS
Welcome!
Welcome to the Serverless Data Processing on AWS workshop!
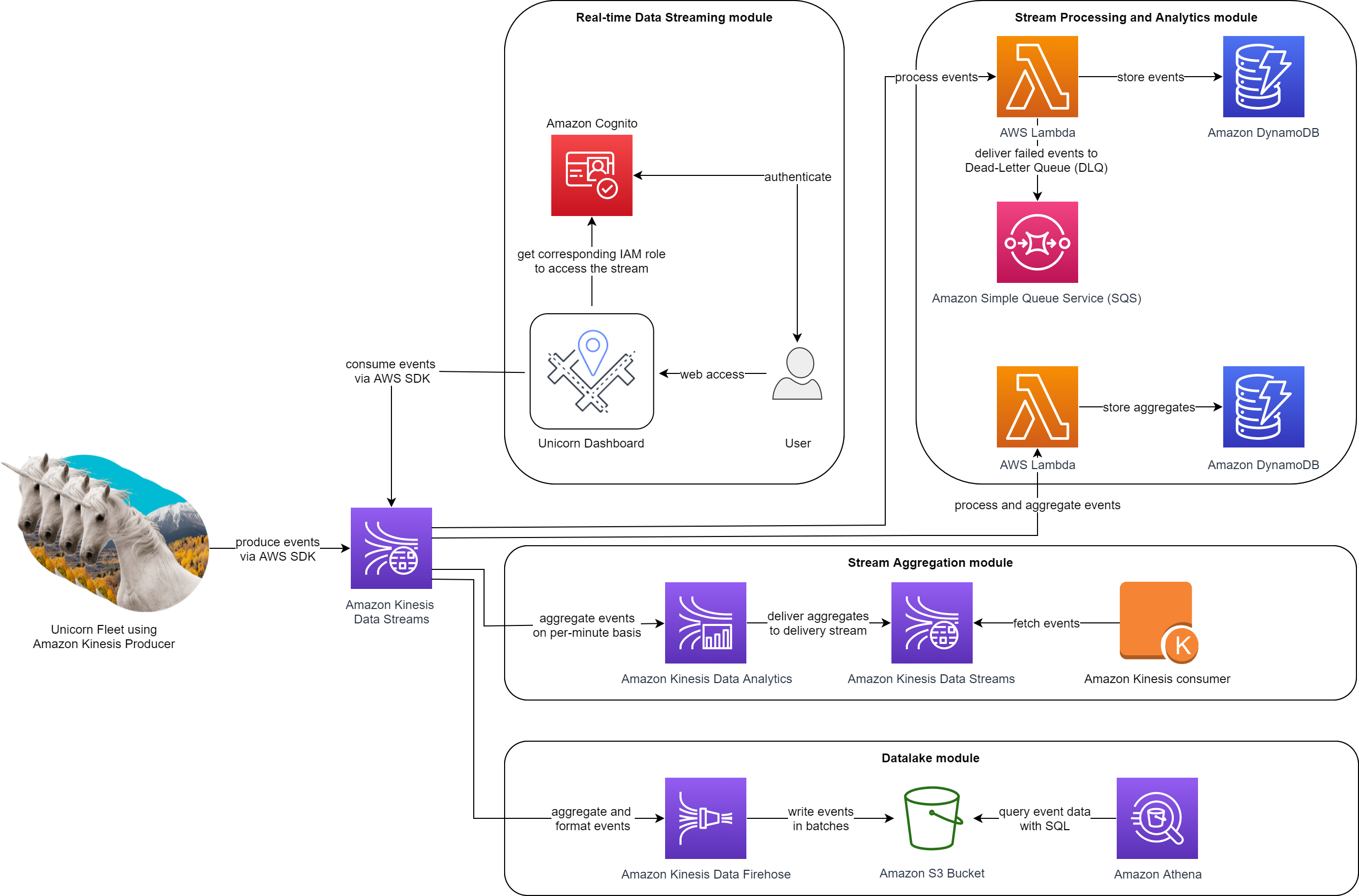
This is a 200-level workshop designed to illustrate how to use AWS services to process real-time data streams without managing servers. In this workshop, we’ll help the fictive company Wild Rydes. Wild Rydes introduces an innovative transportation service that offers unicorn rydes to help people to get to their destination faster and hassle-free. Each unicorn is equipped with a sensor that reports its location and vital signs. During this workshop, we’ll build infrastructure to enable operations personnel at Wild Rydes to monitor the health and status of their unicorn fleet. We’ll use AWS to build applications that process and visualize the unicorn data in real-time.
We will use a variety of AWS services including: Amazon Kinesis, AWS Lambda, Amazon Simple Storage Service (Amazon S3), Amazon DynamoDB, Amazon Cognito, and Amazon Athena. We’ll use:
- Lambda to process real-time streams,
- DynamoDB to persist unicorn vitals,
- Amazon Kinesis Data Analytics to build a serverless application to aggregate data,
- Amazon Kinesis Data Firehose to archive the raw data to Amazon S3,
- and Athena to run ad-hoc queries against the raw data.
The final architecture when completing this workshop will be:
Modules
This workshop is divided into four modules. Each module describes a scenario of what we’re going to build and step-by-step directions to help you implement the architecture and verify your work.
| Module | Description |
|---|---|
| Real-time Streaming Data | Create a stream in Kinesis and write to and read from the stream to track Wild Rydes unicorns on a live map. In this module you’ll also create an Amazon Cognito identity pool to grant the live map access to your stream. |
| Stream Processing | Process data from Kinesis Data Streams using AWS Lambda and learn about different error handling mechanisms. You will also explore stream analytics with AWS Lambda tumbling window feature. |
| Streaming Aggregation | Build a Kinesis Data Analytics application to read from the stream and aggregate metrics like unicorn health and distance traveled each minute. |
| Data Lake | Use Kinesis Data Firehose to flush the raw sensor data to an S3 bucket for archival purposes. Using Athena, you’ll run SQL queries against the raw data for ad-hoc analysis. |
Modules 1 and 2 are intended to be executed linearly. You can then choose to do either Module 3 or 4 depending on your time as they are independent of each other, or you can do them sequentially.
Issues, Comments, Feedback?
I’m open source! If you see an issue, want to contribute content, or have overall feedback please open an issue or pull request.
Next
✅ Review and follow the directions in the setup guide, wherein you’ll configure your AWS Cloud9 IDE and setup pre-requisites like an AWS Account