Stream Processing
Implementation
In the SetUp section, we set up the all the necessary services and roles required to read a message from Amazon Kinesis Data Stream wildrydes by the Lambda function WildRydesStreamProcessor. This function processes the records and inserts the data into Amazon DynamoDB table UnicornSensorData.
Lambda reads records from the data stream and invokes your function synchronously with an event that contains stream records. Lambda reads records in batches and invokes your function to process records from the batch. Each batch contains records from a single shard/data stream. Follow this link to learn more about this integration
In this module, you’ll send streaming data to Amazon Kinesis Data Stream, wildrydes using the producer.go library and use the AWS Console to monitor Lambda’s processing of records from the
wildrydes stream and query the results in Amazon DynamoDB.
1. Produce streaming data
-
Return to you AWS Cloud9 instance and run the producer to start emitting sensor data to the stream with a unique unicorn name.
./producer -name Shadowfax -stream wildrydes -msgs 20
2. Verify Lambda execution
Verify that the trigger is properly executing the Lambda function. View the metrics emitted by the function and inspect the output from the Lambda function.
✅ Step-by-step Instructions
-
Return to the AWS Lambda function console. Click on the Monitor tab and explore the metrics available to monitor the function.
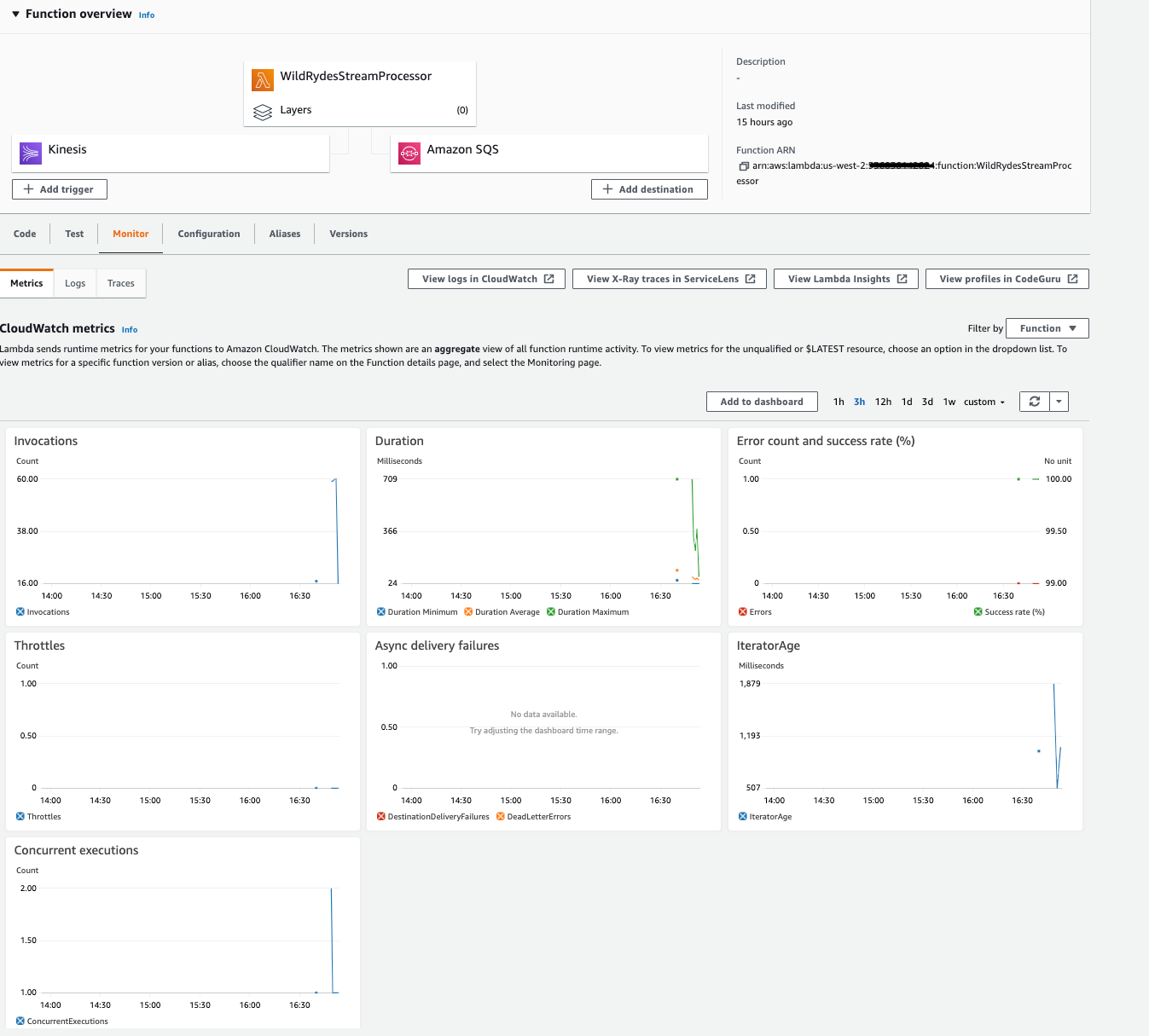
-
Click on Logs to explore the function’s log output.
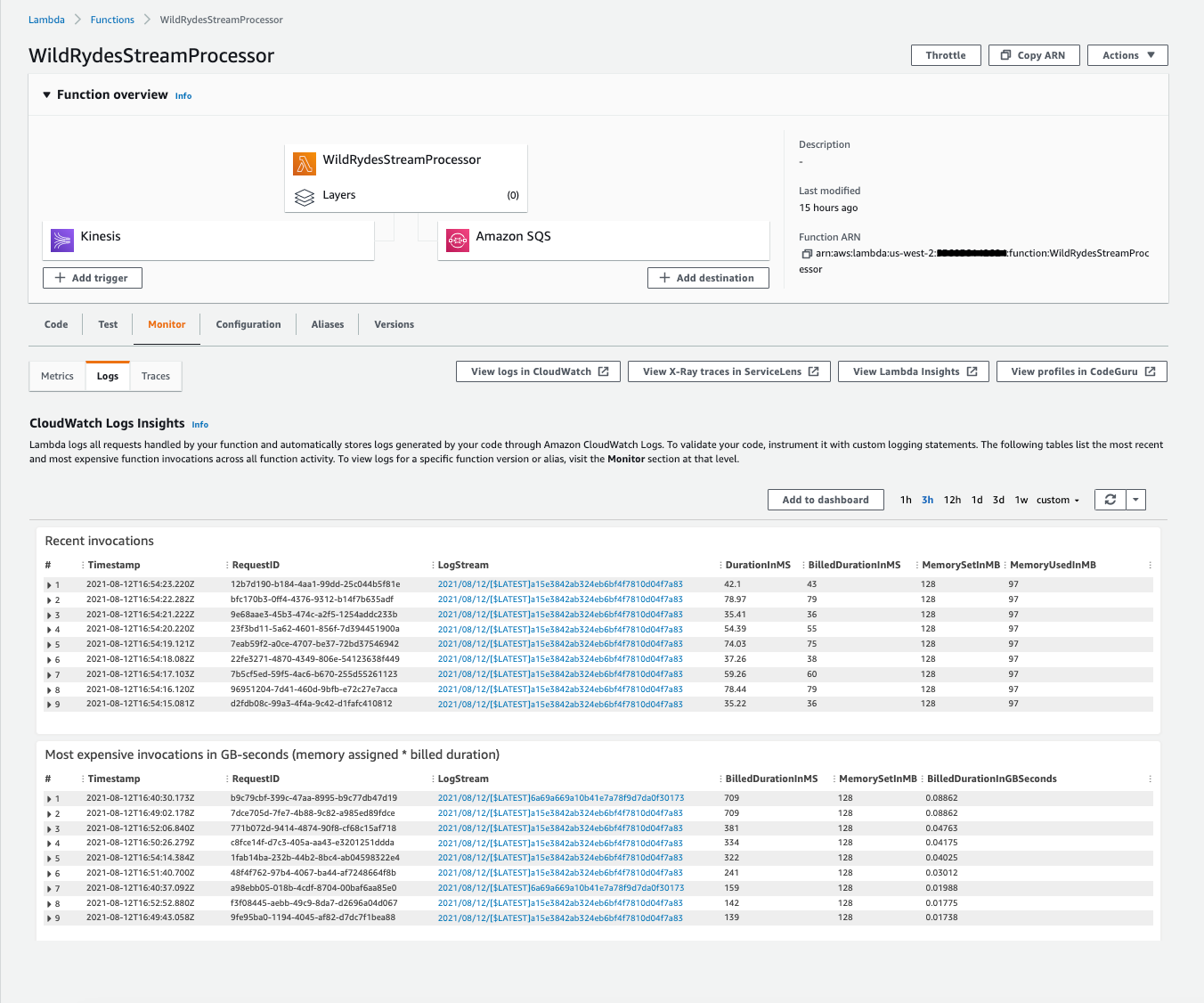
-
Click on View logs in CloudWatch to explore the logs in CloudWatch for the log group /aws/lambda/WildRydesStreamProcessor
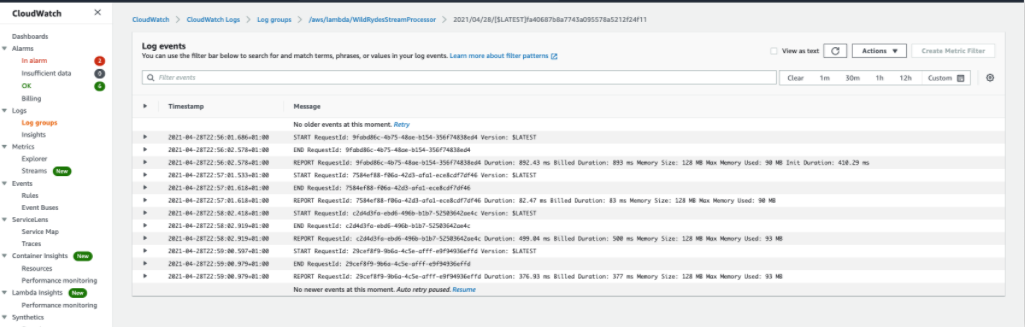



The log groups can take a while to create so if you see “Log Group Does Not Exist” when pressing “View Logs” in CloudWatch then just wait a few more minutes before hitting refresh.
3. Query the DynamoDB table
Using the AWS Management Console, query the DynamoDB table for data for a specific unicorn. Use the producer to create data from a distinct unicorn name and verify those records are persisted.
✅ Step-by-step Instructions
-
Click on Services then select DynamoDB in the Database section.
-
Click Tables from the left-hand navigation
-
Click on UnicornSensorData.
-
Click on the Explore table items button at the top right. Here you should see the Unicorn data for which you’re running a producer.
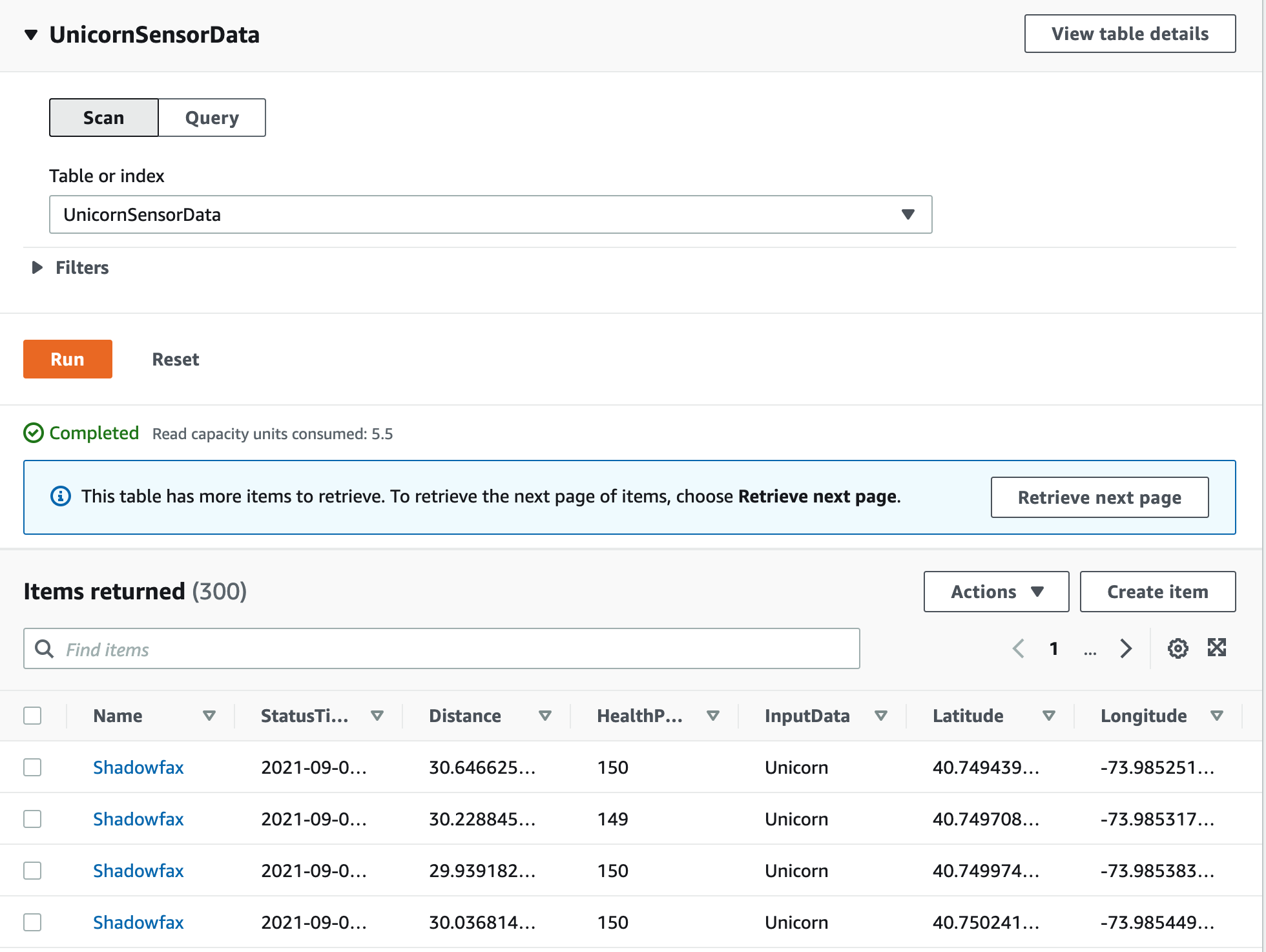

By default, There is one to one mapping between Kinesis shard to Lambda function invocation. You can configure the ParallelizationFactor setting to process one shard of a Kinesis with more than one Lambda invocation simultaneously. If you increase the number of concurrent batches per shard, Lambda still ensures in-order processing at the partition-key level. Follow the link to learn more about parallelization.
⭐ Recap
🔑 You can subscribe Lambda functions to automatically read batches of records off your Kinesis stream and process them if records are detected on the stream.
🔧 In this module, you’ve created a Lambda function that reads from the
Kinesis Data Stream wildrydes and saves each row to DynamoDB.
Next
✅ Proceed to the next module, Error Handling, wherein you’ll explor the various options for handling errors when processing records from a Kinesis Data Straem with Lambda.